This is a research on isolation measures of Kubernetes multi tenancy cluster. We just collected information and wrote a report.
For the current Kubernetes multi tenancy architecture, we could use many different policies to secure the whole system, like network policy, RBAC and so on. But policies are not enough for security isolation. Maybe we could use Hierarchical Namespace Controller to solve this problem. However, the Kubernetes was not designed for multi-tenancy, so it could handle single tenancy but cannot handle multi tenancy well. Then, we will talk about a new architecture which was invented and improved by Alibaba Group.
Let’s take a look at this cutting-edge container-orchestration technology.
Security Isolation of Kubernetes multi tenancy Cluster
Team members: Mou Zhang, Qingshan Zhang, Xiangjun Ma
background
Kubernetes
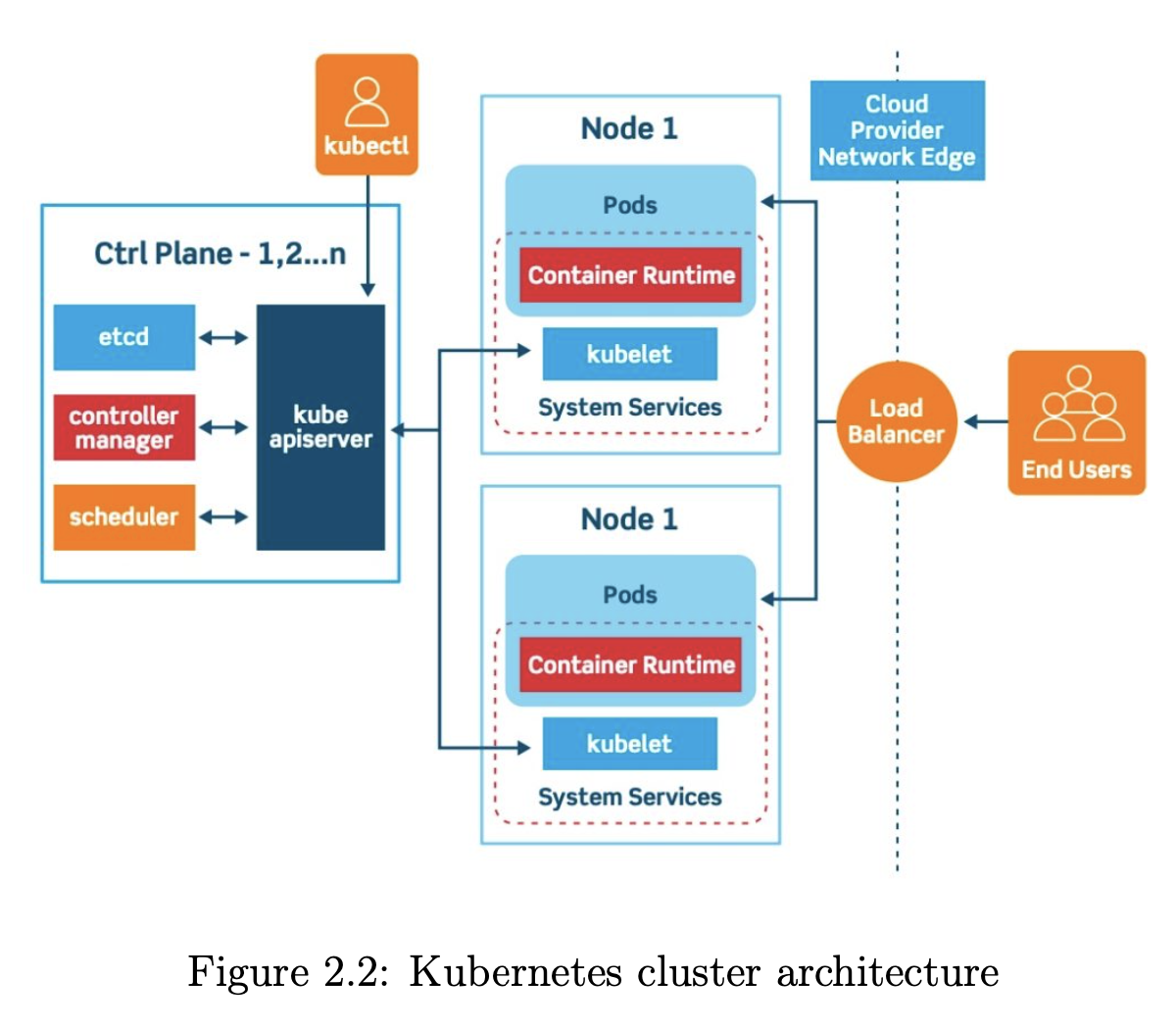
The Figure describes an example of Kubernetes architecture of a cluster with three nodes, including two worker nodes for handling workloads and one control plane node. The control plane ensures that every object in the cluster achieves its declared state. The control plane consists of the following main components:
- Kubernetes API server receives requests and sends responses to the user. By communicating with the Kubernetes API server using the Kubernetes API, users can load their pre-defined object configurations to the cluster, including their choices of the application images, number of replicas, CPU power and storage consumed by each container. Besides, this server acts as the cluster gateway. More precisely, this API server is the only endpoint to send commands and update cluster information. For this reason, it is expected to be accessed from the outside.
- Etcd is a key-value database that stores the records of all Kubernetes objects, such as the current state and the configuration. Any declarative configuration sent from users is persisted in etcd.
- Kubernetes controller manager controls the state of controllers. A controller is a logical entity that maintains the status of one object, and the controller manager is the daemon that implemented all the controllers.
- Scheduler is responsible for allocating containers to worker nodes. The scheduler guarantees that workloads are distributed within the pre-defined constraints.
- Kubelet receives a set of pod specifications from the Kubernetes API server and ensures that containers running on the worker nodes are healthy and follow the pod specifications.
To interact with the cluster, cluster users, such as administrators or de- velopers, need to communicate with the API server using the Kubernetes API. This API is an HTTP API, and thus users can use an HTTP client, e.g., curl or wget, to send API requests. However, for convenience and enhancing productivity, a dedicated tool, kubectl, is introduced for controlling the Kubernetes cluster from a client endpoint. This useful tool allows users to perform all possible actions, including to create, delete, get, describe, and apply. The details of the actions can be found in.
Kubernetes Multi-Tenancy
- Multi-tenancy is a mechanism that allows different customers to access one software instance
- Kubernetes, unfortunately, is originally designed to serve one tenant per cluster only => a new class of management and security issues
- issues include: fairly distributing resources, resources isolation(security). Resources include computation, memory, storage, and network.
- Soft multi-tenancy: trust each other, Hard multi-tenancy is otherwise
- Hard multi-tenancy needs more exploratory on security
Kubernetes network
Hard multi-tenancy network isolation
- network policy(namespace-scoped object bind to a Kubernetes namespace): tenants want to customize network policy objects for their use => custom network policies can overwrite the administrator’s default policies => break network isolation
- Istio service mesh only solve the management problem: service mesh runs on top of the Kubernetes network => pod communication can bypass this overlay layer => no way to isolate the network
Kubernetes multi-tenancy policy configuration
Access Control
AuthN, AuthZ and Admission
In Kubernetes, the control access mainly contains three steps: authentication (AuthN), authorization (AuthZ), and admission control. These steps are shown in the picture.
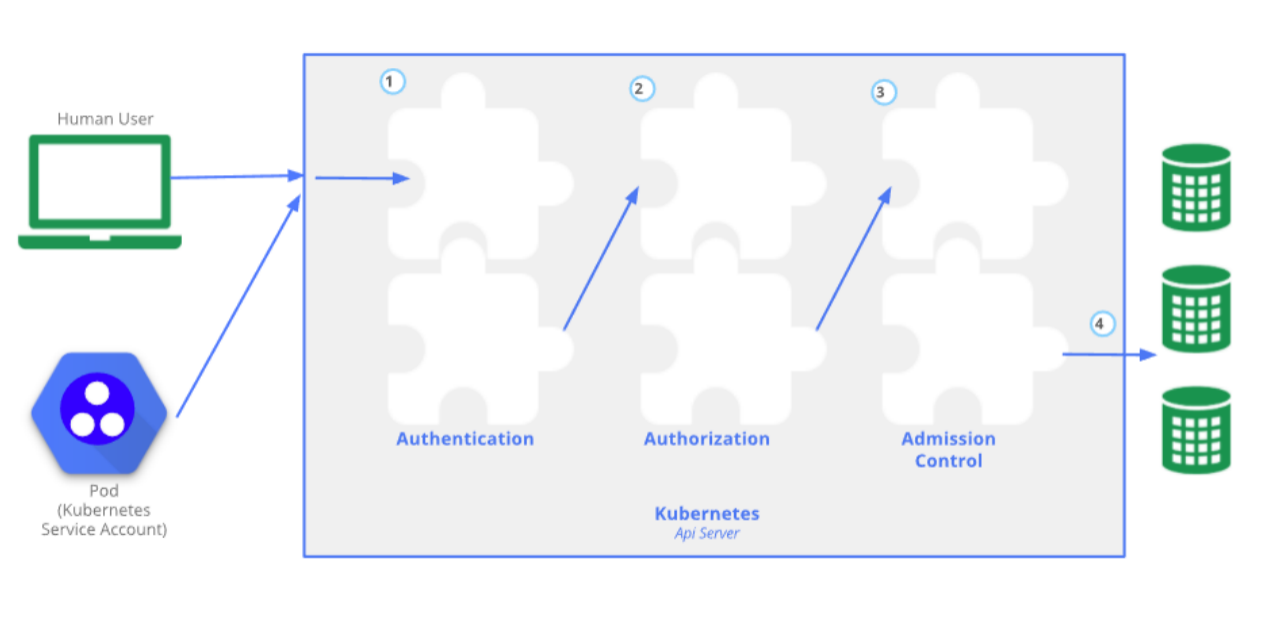
Authentication is the act of proving an assertion, such as the identity of a computer system user. In contrast with identification, the act of indicating a person or thing’s identity, authentication is the process of verifying that identity. It mainly deals with the problem of who is the person.
Authorization is the function of specifying access rights/privileges to resources, which is related to general information security and computer security and to access control in particular. The primary purpose is to figure out what should this user or system be allowed to access.
Admission control is a validation process in communication systems where a check is performed before a connection is established to see if current resources are sufficient for the proposed connection. It is the last step in the access control process, and its primary role is to control the amount of traffic injected to the network, so are parts works as they supposed to be.
A famous and widely used example here is the access control strategy called RBAC. RBAC stands for role-based access control. It is an approach to restricting system access to authorized users. By setting up many roles for different purposes and authorization, RBAC can help to deal with the multi-tenancy problem. It may prevent malicious access to other user’s data and service.
RBAC:
Network Policy
NetworkPolicies are an application-centric construct which allows you to specify how a pod is allowed to communicate with various network “entities” over the network. You may use it.
In the original Kubernetes, you are allowed to set up network policies to prevent the security problem. This can help you control the traffic flow at the IP or port level. You may also add other rules like whitelist to open the communication between different tenants.
An example network policy may look like this:
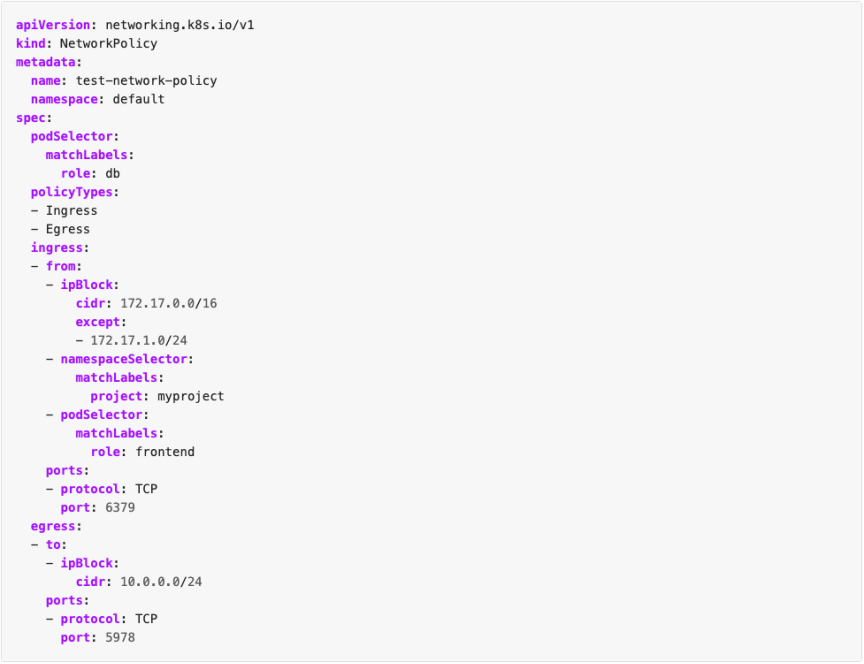
There is already an open-source project supporting this solution.
In the multi-tenancy, the network policy can play a significant role. By setting up network restriction and whitelist, network policy may contribute a lot to the prevention of Unauthorized access and improving communication between different users.
Pod Security Policy
A Pod Security Policy is a cluster-level resource that controls security sensitive aspects of the pod specification. It defines a set of conditions that a pod must run with in order to be accepted into the system, as well as defaults for the related fields. According to the documentation of Kubernetes, you may set rules for host namespaces, host networking and ports, user and group IDs of the container, etc. You may also give permissions of privileged containers, and restrict drive types.
This is a potent tool, and it is easy to set up. You may write your policy in a file and use RBAC to authorize the use of policies.
In the multi-tenancy Kubernetes, this is a good improvement for the RBAC, and make the multi-tenancy safer.
OPA
OPA is another way to manage the admission control in Kubernetes. OPA stands for Open Policy Agent, is designed as a policy-based control for cloud-native environments. Its purpose is to design a flexible, fine-grained control for administrators across the stack. Currently, OPA is designed for Kubernetes, envoy and application for authorization.
In Kubernetes, Admission Controllers enforce semantic validation of objects during creating, update, and delete operations. With OPA you can enforce custom policies on Kubernetes objects without recompiling or reconfiguring the Kubernetes API server.
You may use OPA to replace RBAC to provide a more detailed and customized setting for access control.
In the multi-tenancy Kubernetes, this serves as a better replacement of RBAC, which provides better access control.
Resource Scheduling
Resource Quotas and Limit Range
Resource quota is designed to provide constraints that limit aggregate resource consumption per namespace. When there are multiple users using resources at the same time, they may tend to acquire resources as much as they can. Therefore, a policy is needed to distribute different resources among these users. Using Resource quotas, the user may set up a max limit of how many resources they use, so there will be appropriate resources for all teams.
Limit Range is used to setting the default resource for pods. These tools are beneficial when using multi-tenancy in Kubernetes. It will help balance the resources for different users and prevent any user from getting too much or too few resources.
Pod Priority and Preemption
In real-world problems, there is always a priority among other staffs. There are also priorities for different users who are dealing with different problems. When using multi-tenancy, there should also be a priority to help better organize the queue and get better resources distribution. Therefore we may set priority for pods. The priority indicates the importance of a Pod relative to other Pods. If a Pod cannot be scheduled, the scheduler tries to preempt (evict) lower priority Pods to make scheduling of the pending Pod possible. With the help of pod priority, the availability of essential business applications in the tenant is protected.
Dedicated Nodes
In Kubernetes, taints are designed to allow a node to repel a set of pods. Tolerations are applied to pods, and allow the pods to schedule onto nodes with matching taints.
For example, let us assume you add a taint to a node called node1 using kubectl taint. The command should be like ‘kubectl taint nodes node1 key=value:NoSchedule’. Then no pod will be able to schedule onto node1 unless it has matching toleration.
However, malicious tenants add the same tolerance configuration to their pods to access this node. Therefore, using the node tainting and tolerance mechanism alone cannot ensure the exclusivity of target nodes in a non-trusted multi-tenant cluster.
Protection of Sensitive Information
Secrets Encryption at REST
In Kubernetes, etcd is the place to store the data for users. When there are multiple users, then it would be perilous because the data may be exposed to users that you do not want to show. Therefore, data encryption is necessary.
The original Kubernetes has provided the way to help to encrypt confidential data at rest. The details are in the documentation.
The Hierarchical Namespace Controller [HNC]
- A Kubernetes extension that provides configuration management that makes the namespaces hierarchical natively
features
- Entirely Kubernetes-native, no new concept, but compatible with existing Gitops tools (e.g. Flux).
- Builds on regular Kubernetes namespaces, plus:
- Delegated subnamespace creation without cluster privileges
- Cascading policies, secrets, configmaps, etc.
- Trusted labels for policy application (e.g. Network Policies)
- Easy to extend and integrate
security evaluation
pros
- control panel isolation is ensured by namespace
- Security policies(identity, quotas and other policies) can be easily applied across namespaces
- polices configurations follows the hierarchical structure
cons
- real-world solution is not limited to a hierarchical structure, for example, labelling
- for labelling solutions that are based on policy configuration, it is easy to make configuration mistakes thus hard to address security issues
The Virtual Cluster Solution
Introduction
One challenge for any hard multi-tenancy solution in Kubernetes is to deal with the tenant network isolation. Since the Kubernetes network model is a flat hierarchy, tenant network isolation can easily break the Kubernetes Services. In Virtual Cluster, a concept of tenant network namespace which serves as the central hub for all tenant pods network traffic in the physical node is introduced.
Virtual Cluster Architecture
Instead of changing the Kubernetes APIServer and resource model, the team in Alibaba tried to build a “Virtual Cluster” multi-tenancy layer without changing any code of Kubernetes. With this architecture, every tenant will be assigned a dedicated K8s control plane (Kube-API server + Kube-controller-manager) and several “Virtual Node” (pure Node API object but no corresponding kubelet), so there are no worries for naming or node conflicting at all. In contrast, the tenant workloads are still mixed running in the same underlying “Super Cluster”, so resource utilization is guaranteed.
An Overview of Virtual Cluster
- Each tenant owns a dedicated Kubernetes control plane, i.e., a tenant master, including upstream API Server, controllers and etcd. The tenant control plane is not responsible for scheduling.
- The nodes in tenant master are virtual resources backed by the tenancy resource provider, i.e., a super master. The tenant master and the virtual nodes together form a virtual cluster.
- Virtual Cluster provides hard multi-tenancy leveraging sandbox container runtime and CNI/CSI plugins.
- Virtual Cluster aims to be an upstream Kubernetes native solution. No modifications on upstream Kubernetes control plane are required.
*By allowing multiple tenants to share the same physical node with a unified scheduler, Virtual Cluster can achieve high resource utilization for super master.
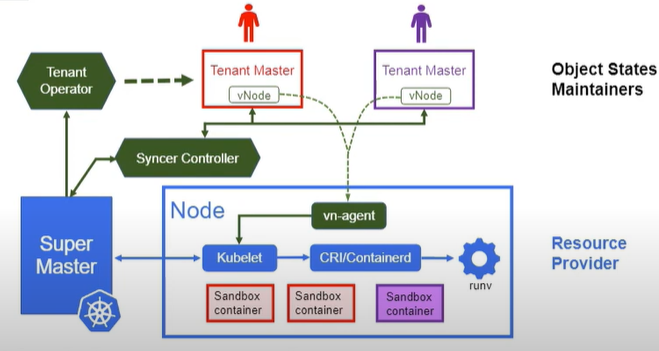
First of all, the physical nodes are managed by the super master, which means the Kubelet in each node connects to the super master only. Each tenant is granted a dedicated tenant master with full API support. Each node in the tenant master is just an API object mapping to a virtual node agent, which is referred to as VN-agent. DaemonSet manages VN-agents. Each serves as a proxy to forward all “Kubelet” API calls from tenant master to the actual Kubelet. The virtual cluster controller manages the tenant life cycle. Also, a syncer controller continuously synchronizes the API objects between tenant masters and super master. A unified scheduler is used to schedule the tenant Pods in super master. Lastly, the objects to tenant mappings in the super master are maintained in the tenant object.
VirtualCluster is composed of the following components
VC-manager: A new CRD VirtualCluster is introduced to model the tenant master. VC-manager manages the lifecycle of each VirtualCluster custom resource. Based on the specification, it either creates Episerver, etcd and controller-manager Pods in local K8s cluster, or imports an existing cluster if a valid kubeconfig is provided.
syncer: A centralized controller that populates API objects needed for Pod provisioning from every tenant master to the super master, and bi-directionally syncs the object statuses. It also periodically scans the synced objects to ensure that the states between tenant master and super master are consistent.
vn-agent: A node daemon that proxies all tenant kubelet API requests to the kubelet process that running in the node. It ensures each tenant can only access its Pods in the node.
With all above, from the tenant’s perspective, each tenant master behaves like an intact Kubernetes with nearly full API capabilities.
Although Virtual Cluster architecture does not change the Kubernetes core, many common workflows are still affected. For example, the Pod creation workflow in Virtual Cluster becomes
- Tenant creates Pod in tenant master
- The sync manager copies the Pod from tenant master to super master. It adds tenant prefix to Pod name, label *key/values, etc. to avoid conflicts;
- Unified scheduler chooses a node for the Pod in super master;
- Kubelet creates the Pod in the selected node;
- The sync manager creates (if it does not exist) a node object in tenant master using the selected node’s VN-agent runtime info. It then updates the Pod status back to the tenant master.
In the end, from the tenant perspective, the Pod runs in a “Node” whose kubelet is the VN-agent.
Comparison Between Virtual Cluster Architecture and Normal Architecture
They share the same tenant concept - A tenant is a client of a fixed and isolated amount of computing, storage, networking, and control plane resources within a Kubernetes cluster.
In Namespace Group, tenants share the same control plane. In contrast, Virtual Cluster provides a dedicated control plane to each tenant at the cost of additional resources for running tenant master.
In Namespace Group, tenancy resources are organized by namespaces while in Virtual Cluster, tenancy resources are presented as a “real” Kubernetes cluster with full API support.
Namespace Group relies on RBAC to provide API level isolation. Virtual cluster naturally provides strong API level isolution, and the tenant concept is decoupled from the Kubernetes core by tenant controller.
Evaluation
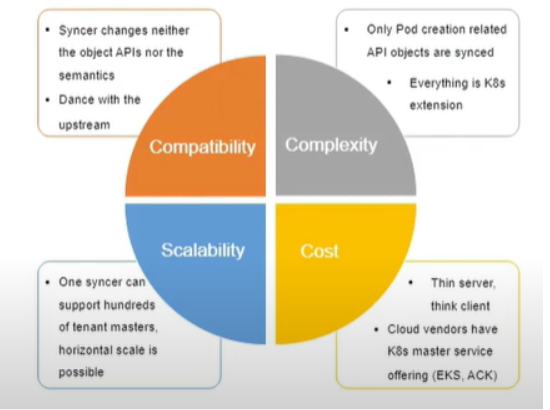
Compatability
It does not change the existing API and semantics, and it could always support upstream Kubernetes versions, so there is no integration cost. In Virtual Cluster, each virtual node has a one-to-one mapping to the actual physical node, which means the pod affinity and the pattern of affinity semantics are the same as before. However, virtual kubelet does not necessarily represent a physical node. In many cases, it represents a group of nodes. Hence, node semantic changed.
Complexity
Syncer only synchronizes 12 object APIs from the tenant master to the super master, not all of the tenant objects. Besides, everything is done using the Kubernetes extensions. So the complexity is limited.
Scalability
One syncer could handle hundreds of tenant masters without much performance impact. So this solution is scalable.
Cost
A common question about Virtual Cluster is the cost of tenant master. It is a legitimate concern for cases where tenants only need a small number of resources to run a few Pods. For those use cases, Namespace Group is more suitable.
However, the cost of tenant master is not critical since a) tenant typically requires a large number of resources to run many Pods; b) Various techniques have been applied to reduce the control plane cost. Overall, we see Virtual Cluster as a supplementary solution to Namespace Group to deal with different use cases.
Benefits
No noisy neighbours anymore and every tenant cannot see other tenants at all. If one tenant hits the security vulnerability, only that tenant get affected. The tenant user has full control over the tenant master, which provides good user experience.
Current Support Environment
VirtualCluster passes most of the Kubernetes conformance tests. One failing test asks for supporting subdomain, which cannot be quickly done in the VirtualCluster architecture.
Here are other considerations that users should be aware of:
VirtualCluster follows a serverless design pattern. The super master node topology is not fully exposed to tenant master. Only the nodes that tenant Pods are running on will be shown in tenant master. As a result, VirtualCluster does not support DaemonSet alike workloads in tenant master. In other words, the syncer controller rejects a newly created tenant Pod if its node name has been set in the spec.
It is recommended to increase the tenant master node controller –node-monitor-grace-period parameter to a more considerable value ( >60 seconds, done in the sample cluster version yaml already). The syncer controller does not update the node lease objects in tenant master. Hence the default grace period is too small.
Coredns is not tenant-aware. Hence, the tenant should install coredns in tenant master if DNS is required. The DNS service should be created in Kube-system namespace using the name Kube-DNS. The syncer controller can then recognize the DNS service cluster IP in super master and inject it into Pod spec dnsConfig.
VirtualCluster supports tenant DNS service using a customized coredns build. See this document for details.
VirtualCluster fully support tenant service account.
VirtualCluster does not support tenant PersistentVolumes. The super master provides all PVs and Storage classes.
It is recommended that tenant master and super master should use the same Kubernetes version to avoid incompatible API behaviours. The syncer controller and vn-agent are built using Kubernetes 1.16 APIs, hence higher Kubernetes versions are not supported at this moment.
Reference
[1] T. K. API, “The kubernetes API,” Kubernetes. Oct. 2020, [Online]. Available: https://kubernetes.io/
docs/concepts/overview/kubernetes-api/.
[2] O. of kubectl, “Overview of kubectl,” Kubernetes. Nov. 2020, [Online]. Available: https://kubern
etes.io/docs/reference/kubectl/overview/.
[3] X. Nguyen and others, “Network isolation for kubernetes hard multi-tenancy,” 2020.
[4] “Authentication,” Wikipedia. 2020, [Online]. Available: https://en.wikipedia.org/wiki/Authentica
tion.
[5] “Authorization,” Wikipedia. 2020, [Online]. Available: https://en.wikipedia.org/wiki/Authorizatio
n.
[6] “Admission control,” Wikipedia. 2020, [Online]. Available: https://en.wikipedia.org/wiki/Admiss
ion_control.
[7] “Role-based access control,” Wikipedia. 2020, [Online]. Available: https://en.wikipedia.org/wiki/
Role-based_access_control.
[8] N. Policies, “Network policies,” Kubernetes. Nov. 2020, [Online]. Available: https://kubernetes.i
o/docs/concepts/services-networking/network-policies/.
[9] ahmetb, “Ahmetb/kubernetes-network-policy-recipes,” GitHub. Nov. 2020, [Online]. Available:
https://github.com/ahmetb/kubernetes-network-policy-recipes.
[10] ahmetb, “Ahmetb/kubernetes-network-policy-recipes,” GitHub. Nov. 2020, [Online]. Available:
https://github.com/ahmetb/kubernetes-network-policy-recipes.
[11] P. S. Policies, “Pod security policies,” Kubernetes. Oct. 2020, [Online]. Available: https://kubern
etes.io/docs/concepts/policy/pod-security-policy/.
[12] Open Policy Agent. 2020, [Online]. Available: https://www.openpolicyagent.org/docs/v0.12.2/k
ubernetes-admission-control/.
[13] R. Quotas, “Resource quotas,” Kubernetes. Nov. 2020, [Online]. Available: https://kubernetes.io/
docs/concepts/policy/resource-quotas/.
[14] P. Priority and Preemption, “Pod priority and preemption,” Kubernetes. Oct. 2020, [Online].
Available: https://kubernetes.io/docs/concepts/configuration/pod-priority-preemption/.
[15] Taints and Tolerations, “Taints and tolerations,” Kubernetes. Nov. 2020, [Online]. Available:
https://kubernetes.io/docs/concepts/scheduling-eviction/taint-and-toleration/.
[16] E. S. D. at Rest, “Encrypting secret data at rest,” Kubernetes. May 2020, [Online]. Available:
https://kubernetes.io/docs/tasks/administer-cluster/encrypt-data/?spm=a2c4e.10696291.0.0.
1d0419a4u28oFT.
[17] “Virtual cluster - extending namespace based multi-tenancy with a cluster view | cloud native
computing foundation,” Cloud Native Computing Foundation. Jun. 2019, [Online]. Available:
https://www.cncf.io/blog/2019/06/20/virtual-cluster-extending-namespace-based-multitenancy-with-a-cluster-view.
[18] “A virtual cluster based kubernetes multi-tenancy design,” Alibaba team virtual cluster proposal.
Nov. 2020, [Online]. Available: https://docs.google.com/document/d/1EELeVaduYZ65j4AXg9bp
3Kyn38GKDU5fAJ5LFcxt2ZU/edit#heading=h.zgjbixz8dbin.
[19] “Virtual cluster - a practical kubernetes hard multi-tenancy solution,” youtube. Sep. 2020, [Online].
Available: https://www.youtube.com/watch?v=5RgF_dYyvEY.
[20] “Kubernetes-sigs/multi-tenancy,” GitHub. Nov. 2020, [Online]. Available: https://github.com/kub
ernetes-sigs/multi-tenancy/tree/master/incubator/virtualcluster.



